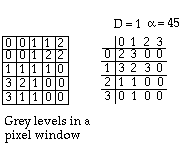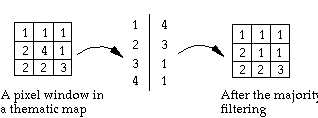7.4 Non-Conventional Classification Algorithms
1. By conventional classification, we refer to the algorithms which make the use of only multi-spectral information in the classification process.
2.
3. The problem with multi-spectral classification is that no spatial information on the image has been utilized. In fact, that is the difference between human interpretation and computer-assisted image classification. Human interpretation always involves the use of spatial information such as texture, shape, shade, size, site, association etc. While the strength of computer technique lag is on the handling of the grey-level values in the image, in terms of making use of spatial information, computer technique lag for behind. Therefore, it is an active field in image understanding (which is a subfield of pattern recognition, or artificial intelligence to make use of spatial patterns in an image).
We can summarize three general types of non-conventional classification:
Preprocessing approach,
Post processing approach, and
Use of contextual classifier.
Diagram 1 shows the procedures involved in a preprocessing method. The indispensable part of a preprocessing classification method is the involvement of spatial-feature extraction procedures.
Thanks to the development in the image understanding field, we are able to use part of the spatial information in image classification. Overall, there are two types of approaches to make use of spatial information.
- Region-based classification (object-based)
- Pixel window-based classification
Object-based classification
In order to classify objects, one has to somehow partition the original imagery. This can be done with image segmentation techniques that have been introduced previously, such as thresholding, region-growing and clustering.
The resultant segmented image can then be passed on to the region extraction procedure, where segments are treated as a whole object for the successive processing.
For instance, we can generate a table for each object as an entity table. From the entity table, we can proceed with various algorithms to complete classification, or prior to classification, we may do some preprocessing, such as filtering out some small objects.
We may have to base our classification decision on some neighbourhood information. Gong and Howarth (1990) have developed a knowledge-based system to conduct a region-based (object-based) classification.
4. Pixel-window based classification
In a pixel-window based classification, a labelling decision is made for one pixel according to the multi-spectral data. This data contains information on not only the pixel but also its neighbourhood.
A pixel window can be of any size, as long as it does not exceed the size of an image. For computational simplicity, however, odd-sized squares are used.
The grey-level variability within a pixel window can be measured and used in a classification algorithm. The grey-level variability is referred to as texture (Haralick, 1979). The following is some commonly-used texture measures:
(1) Simple statistics transformation
For each pixel-window, we can calculate parameters as in Table 1 (Hsu, 1978; Gong and Howarth, 1993).
TABLE 7.4. STATISTICAL MEASURES USED FOR SPATIAL FEATURE EXTRACTION |
||
Feature Code |
Full Name |
Mathematical Description |
| AVE | Average |
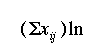 |
| STD | Standard Deviation |
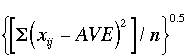 |
| SKW | Skewness |
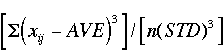 |
| KRT | Kurtosis |
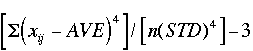 |
| ADA | Absolute Deviation from the Average |
|
| CCN | Contrast Between the Center Pixel and its Neighbors |
|
| ACN | Average Difference Between the Center Pixel and its Neighbors |
|
| CAN | Contrast Between Adjacent Neighbors |
|
| CAS | Sum of the Squared CAN |
|
| CSN | Contrast Between the Second Neighbors |
|
| CSS | Sum of the Squared CSN |
|
| RXN | Range |
|
| MED | Median |
|
| ______________________________________________________________________ | ||
|
Pixel value at location | |
|
Value for the center pixel | |
|
Values for a pair of adjacent pixels | |
|
Values for a pair of every second neighbors | |
|
Number of pixels in the window | |
|
Number of pairs of adjacent neighbors | |
|
Number of pairs of every second neighbor | |
(2) Grey-level co-occurrence matrix method (used to characterize textures)
The matrix is determined by enumerating all possible combination of two grey-levels of pairs of pixels in a pixel window. These pixel-pairs are defined by their distance (D) and angle (a).
From the grey-level co-occurrence matrix, one can generate a number of parameters. (Haralick et al 1973): These include,
Homogeneity
Contrast
Entropy, etc.
Although these methods have been used in many remote sensing applications, they require a large amount of computation and disk space. There are so many parameters that need to be determined, such as size of pixel-window, distance, angle, statistics, etc.
Most of these spatial features can be categorized into two groups. The first group of spatial features is similar to an average filtered image. The second group is similar to an edge-enhanced image.
The simplest example for the post-processing contextual classification is through filtering such as majority filtering.
(3) Majority filter
(4) Grey-level vector reduction and frequency-based classification.
After testing a number of pixel-window based contextual classification algorithms, Gong and Howarth (1992a) found that most of these algorithms either required too much computation, or did not significantly improve classification accuracies when they were applied to the classification of SPOT HRV XS data acquired over an urban area. They developed a procedure called a grey-level vector reduction and a frequency-based classification which was tested using the same SPOT data set and some other data sets, such as TM data and CASI (7.5 m x 7.5 m spatial resolution) data. The results proved that the frequency-based classification method could save a significant amount of computation while achieving high classification accuracies.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()